 乐问 从0到2
乐问 从0到2
作者:admin 日期:2020-01-08
mybaits中foreach与REGEXP结合的用法
作者:admin 日期:2019-06-11
在mybaits中,foreach一般与in语法结合使用居多,与正则regexp结合用的没有见到比较多。刚好有这样的一个接口需求,费了点时间研究,达到想要的效果。
需求:需要查询在某字段中,匹配提交过来的字符的数据
需求描述:
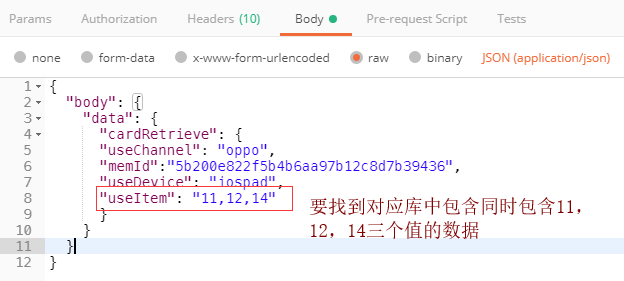
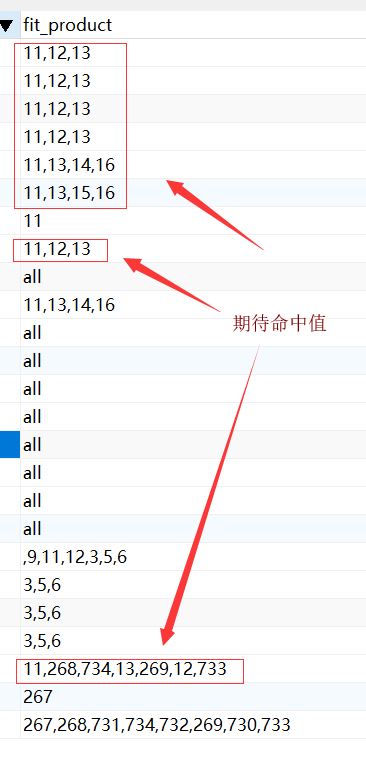
在传值到mappper里时 传进来的值useItem的值是一个以逗号,隔开的字符串值[11,12,13],需要在表中字段fit_product找到同时包含11,12,13三个值的数据 而fit_product在数据库的值也是以逗号,切割存储的。
库中数据
eg:
类似的SQL执行语句
select id,fit_product from card_detail Where fit_product REGEXP '11' AND fit_product REGEXP '12' AND fit_product REGEXP '13' and mem
关键就在这里了,需要很好的处理ope/ separator/close 的值
<if test="useItem != null">
<if test="useItem.indexOf(',') != -1">
AND
<foreach item="item" index="index"
collection="useItem.split(',')" open=" " separator="and " close=" ">
cd.fit_product REGEXP #{item}
</foreach>
</if>
需求:需要查询在某字段中,匹配提交过来的字符的数据
需求描述:
在传值到mappper里时 传进来的值useItem的值是一个以逗号,隔开的字符串值[11,12,13],需要在表中字段fit_product找到同时包含11,12,13三个值的数据 而fit_product在数据库的值也是以逗号,切割存储的。
库中数据
eg:
类似的SQL执行语句
复制内容到剪贴板 程序代码
程序代码
程序代码select id,fit_product from card_detail Where fit_product REGEXP '11' AND fit_product REGEXP '12' AND fit_product REGEXP '13' and mem
关键就在这里了,需要很好的处理ope/ separator/close 的值
复制内容到剪贴板 程序代码
程序代码<if test="useItem != null">
<if test="useItem.indexOf(',') != -1">
AND
<foreach item="item" index="index"
collection="useItem.split(',')" open=" " separator="and " close=" ">
cd.fit_product REGEXP #{item}
</foreach>
</if>
品质大数据项目
作者:admin 日期:2018-07-02
nested exception is: java.net.BindException
作者:admin 日期:2018-06-26
问题:
java.rmi.server.ExportException: Port already in use: 1099; nested exception is: java.net.BindException: Address already in use: JVM_Bind
解决办法:
进入命令提示行
找出占用端口的进程的PID,进入windows命令,查看什么进程占用了1099端口
使用命令:netstat -aon|findstr 1099 找出占用1099端口的进程
闭占用该端口的进程:taskkill -f -pid 3756
MySQL 按日累加求销量 按月累加求销量
作者:admin 日期:2018-05-28
按日累加求销量
复制内容到剪贴板 程序代码
程序代码Select
a.id,
a.product,
a.sale_date,
a.num ,
(
Select
sum(num)
FROM
t_sale_stats b
Where
b.id <= a.id
AND b.product = '产品名称'
AND b.sale_date >= '2015-03-01'
AND b.sale_date <= '2015-03-05'
) cum_num
FROM
t_sale_stats a
Where
a.sale_date >= '2015-03-01'
AND a.sale_date <= '2015-03-05'
AND a.product = '产品名称'
ORDER BY
admin如何在mybatis中调试查看生成的sql语句
作者:admin 日期:2018-05-17
大数据任务调度平台
作者:admin 日期:2017-11-28
Hive 杀进程 删除分区数据
作者:admin 日期:2017-08-31
Hive 自动生成建表语句
作者:admin 日期:2017-07-25
大数据应用之应用场景
作者:admin 日期:2017-06-21
Hive应用sqoop从MS-SQL 和Oracle 全量增量导入至HIVE
作者:admin 日期:2017-05-25
全量导入比较容易,关键在于增量导入
Sqoop导入数据顺序
其实可以把导入的代码固定成脚本,然后只要把库名跟表名换掉就可以了
Sqoop的增量导入要与sqoop的Job关联在一起
全量导入MS-SQL数据至HIVE
复制内容到剪贴板 程序代码
程序代码#Set the RDBMS connection params
rbms_driver='com.microsoft.sqlserver.jdbc.SQLServerDriver'
rdbms_connstr="jdbc:sqlserver://MSSQL数据库主机;username=用户名;password=密码;database=库名"
rdbms_username="MSSQL数据库用户名"
Hive 的字符串UrlDecode 中文解码
作者:admin 日期:2017-05-23
真没想到,原来HIVE自己有Urldecode,原本以为要写一个UDF,结果不然。
业务场景: 某字段基本为中文字符,采集时做了urlEncode处理,入到库中没有解码。
要解决的问题:将encode的数据做urldecode处理
方案一:自构建一个UDF函数,需要继承UDF,实现其evaluate()方法
复制内容到剪贴板 程序代码
程序代码@Description(name = "decoder_url", value = "_FUNC_(url [,code][,count]) - decoder a URL from a String for count times using code as encoding scheme ", extended = ""
+ "if count is not given ,the url will be decoderd for 2 time,"
+ "if code is not given ,GBK is used")
public class UDFDecoderUrl extends UDF {
private String url = null;
private int times = 2;
private String code = "GBK";
public UDFDecoderUrl() {






